- Word count: 1384
- Average reading time: 6 minutes and 55 seconds (based on 200 WPM)
When
Somewhere in the beginning of 2016 and november & a bit in december 2016
What
An attempt to write my own framework for an anonymous concurrent web crawler.
Why
I wanted to crawl multiple second-hand car advertisement websites to analyse and make comparisons and be able to feed it more detailed query's. But most of all I wanted to be able to figure out what kind of car, not necessarily what specific advertisement, but what kind of car would fit my needs the best - with second-hand price being a heavy weighing variable. I know a lot about cars as they're a lifelong hobby of mine but despite that knowledge I still have great difficulty finding the perfect fit.
Why anonymous
After having written a very basic hard-coded script to crawl a specific website I noticed that I got banned fairly quickly due to the high amount of requests. Figuring it wouldn't be feasible to make the large amount of requests necessary to fill such a database from a single IP I started reading into crawlers that go through Tor. I came across this fantastic blog post highlighting some of the requirements for such a structure.
Why not Scrapy
Starting out initially with Scrapy I had some difficulty getting it to work with Tor. Most notably at the time I knew very little about everything involved regarding proxies, headers, cookies, etc. This caused to give me some headaches and arbitrarly changing things without having a clear idea of what exactly I was doing. Because Scrapy is such a solid framework it also manages a lot of things involved with crawling without ever coming in the eyes of the user. One is able to install scrapy and set it up within an hour for a given website if one has an idea of what to do - I didn't.
Why reinvent the wheel
I didn't think I would make a better crawler than Scrapy but I figured I'd learn a couple of things by making it from scratch:
- How to write a larger project than my recent ANPR project
- What exactly happens when a request is made to a webserver and what is visible
- How to make a request through Tor
- How to set-up multiple proxies
- How to make concurrent requests
Aside from the above mentioned things I figured I'd also learn a lot of things that I didn't think of at the time.
Was it succesful?
As a crawler, No. As an educative project, Yes. It was succesful in the sense that I learned a lot about keeping code somewhat clean and tidy, designing logical constructs and reasoning why the architecture of Scrapy is what it is. On top of that I learned a whole lot about the processes involved with web requests, async operations, code design, parsing and a plethora of other things. s a crawler it wasn't very succesful. Yes it can crawl basic HTML webpages but the moment a cookie occurs or something else unexpected pops up the whole thing comes crashing down - there are so many things to consider when coding a stable framework. I can't emphasize enough how much I learned from this.
I hope you enjoy reading some highlights of the things I learned along the way.
How
Anonymous requests
Initially I dived into the documentation of Tor as my highest priority was to make a request over Tor. Having walked through some tutorials I quickly was able to make a request over Tor and get the IP of the Tor exit node.
Multiple proxies
One IP was not enough though, I wanted to make requests over multiple proxies. This is where I started to run into a funny problem. As I was working on Windows at the time I wasn't able to run the commmand
tor --RunAsDaemon 1
This was not supported on Windows and after a while of searching around I figured it might be a good moment to get a Linux install running on my laptop. I did not have a free partition I could use to install an Ubuntu install on and I wasn't planning on wiping my laptop clean just to make the install. I bought a quick USB stick and installed Ubuntu 14.04 on the USB stick and booted the install from there - it wasn't fast nor stable but it worked and I was happy.
Using the bash script of the above mentioned blog post I was able to fire up multiple Tor instances and make requests through them, though still sequential. The bash script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #!/bin/bash
base_socks_port=9050
base_control_port=8118
# Create data directory if it doesn't exist
if [ ! -d "data" ]; then
mkdir "data"
fi
for i in {0..2}
#for i in {0..80}
do
j=$((i+1))
socks_port=$((base_socks_port+i))
control_port=$((base_control_port+i))
if [ ! -d "data/tor$i" ]; then
echo "Creating directory data/tor$i"
mkdir "data/tor$i"
fi
# Take into account that authentication for the control port is disabled. Must be used in secure and controlled environments
echo "Running: tor --RunAsDaemon 1 --CookieAuthentication 0 --HashedControlPassword \"\" --ControlPort $control_port --PidFile tor$i.pid --SocksPort $socks_port --DataDirectory data/tor$i"
tor --RunAsDaemon 1 --CookieAuthentication 0 --HashedControlPassword "" --ControlPort $control_port --PidFile tor$i.pid --SocksPort $socks_port --DataDirectory data/tor$i
done
|
Concurrently
Having talked to some persons in the field about this idea one of them suggested me to look into Eventlet and I must say I was amazed by the simple API they provided and the speed attainable. Having had some help writing the intial functions to make some requests with the aid of this library I was able to fire off some concurrent requests over Tor - though I must say I was amazed about how long those couple of requests actually took. I knew requests over Tor were slow, but that slow was a bit of a shocker.
Making a Pipeline
Being able to fire up multiple Tor instances and making requests through them I wanted to rewrite the code into a structured pipeline so that I would be able write Spiders for whatever websites I wanted to crawl. Writing this pipeline was a process of trial and error and finding out what works and what doesn't work. I wanted to avoid copying Scrapy in its entirety but noticed that the further I developed the pipeline the more and more it began to resemble the architecture chosen by Scrapy. I feel the pipeline is best explained in a flowchart.
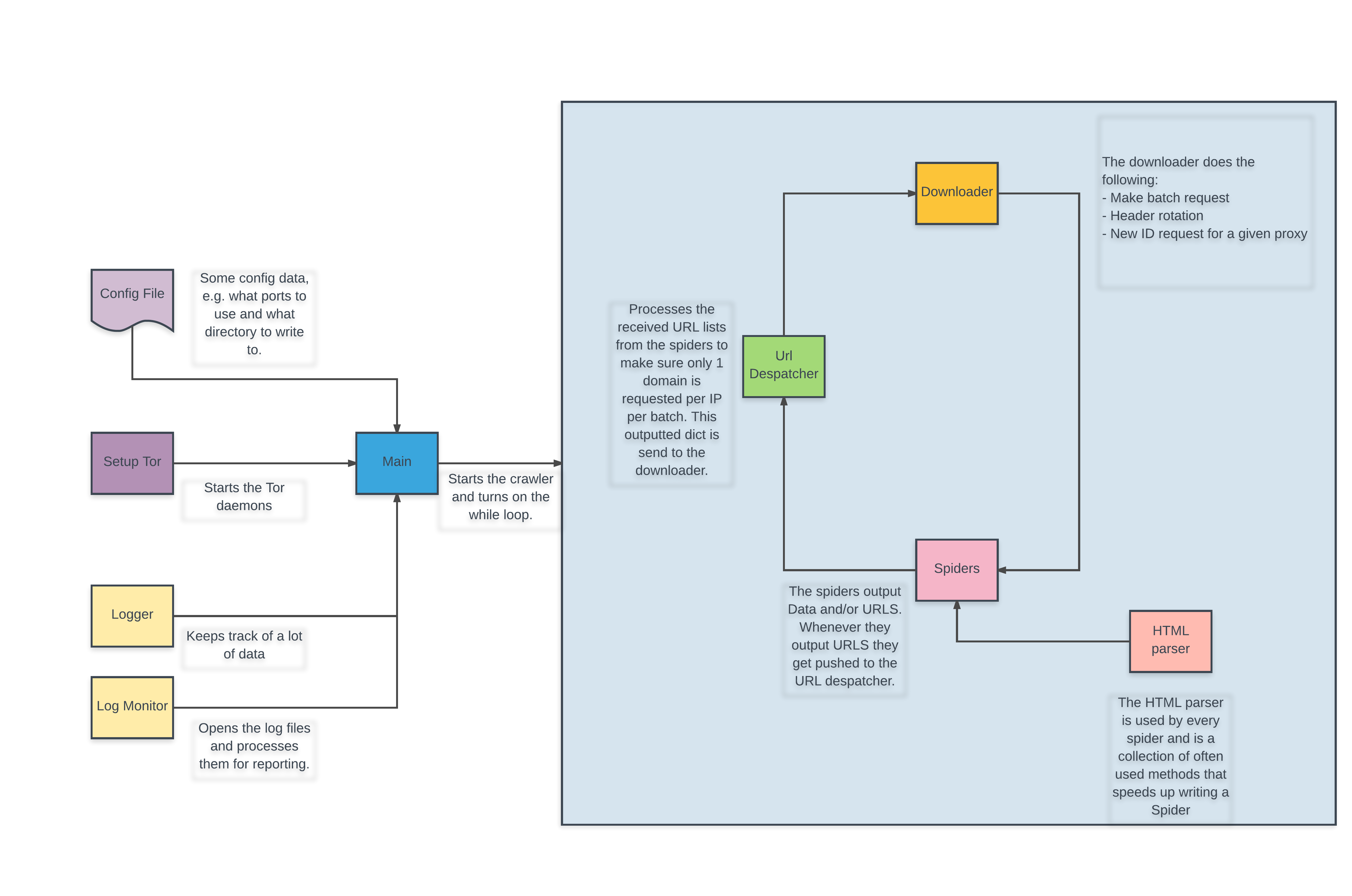
Dropping the project
At this point I had quite some time invested and started to figure out the errors I started with. For example the downloader class as it is now is actually a proxy rotater and a downloader in one class. This was just the tip of the iceberg of errors I needed to correct for this to actually work on a small scale - it'd be far better to divide those functionalities in seperate classes. What actually made me drop the project as a whole was the way I implemented the requesting method. It was hardcoded to be a GET request as I didn't consider handling cookiewalls for example. Having already decided upon a format for which the Spiders provide the urls and how the URL despatcher handles this, I concluded that to fix this mistake, and others, properly I needed to rewrite a lot of the project from scratch.
I learned a lot of valuable lessons regarding web requests, anonymizing, concurrency, threading, and software development. But also that I didn't felt I'd contribute if I'd make another, much worser, python crawler framework. Despite having never crawled a website for more than 10 requests in total (always brief tests) I am glad with the lessons I learned.
The code
Here is a link to the code of my project, it works okay and possibly for a long time as long as there is no need for another method than GET request - so don't plan on using it for anything more than educative purposes.