- Word count: 1224
- Average reading time: 6 minutes and 7 seconds (based on 200 WPM)
When
February 2016
What
A simple analysis tool generating some interesting statistics from a WhatsApp (Wapp) chat. I wrote all the code for this in approx. 4 hours. Rewriting this in a tidy manner and utilizing some libraries it probably can be reduced to approx. 100 lines of code in total (without plotting code). Nevertheless, the code can be found here - it's bad but also very nice to see how much I've grown since then.
Disclaimer: The code used for this has not been altered in any way after the time of writing - I don't think it's fair to alter the code afterwards for a better presentation as this tool was written with the idea of getting results ASAP. I did add a date format changer function & username cleaning function. The date format changer was added to handle the new date format. Somewhere between february 2016 and now Wapp changed it's date format from
xx/xx/xxxxto{x]x/{x]x/xxwith the {x} being optional, and the username cleaning function so that it can be used for group chats as well. Beside these two functions everything is as it was as when I made it in 2016.
Why
My girlfriend has a certain word she uses often and I wanted to find out how often, through her useage I started to use the word as well so a simple Ctrl + F or ^F wouldn't
have worked; I needed to know who said the word how often. While writing some simple code for that I noticed that, while structuring it, I was able to find some other interesting statistics
with relative ease.
How
Writing this in 2017 I do not have a clear recollection anymore of what exactly my first steps were and how this organically grew out of hand. What I do recall is that my initial target was to identify what users were in the chat (Girlfriend & Me) and what words they said and how often.
Splitting the data
The Wapp chatfile is saved as a .txt and is interpreted by Python as a
single string. There are some options to make it interpret in a more useful way but at the time I already knew a simple way to get what I wanted from a single long string.
With this regex command:
text_list = re.split('([\d]*[/][\d]*[/][\d]*)([,][\s])([\d]*[:][\d]*)[\s][-][\s]([a-zA-Z]*[\s]*[^:]*)(:)([a-zA-Z\s]*)', text)
The long string would be split in seperate logical parts, for example this string:
8/7/15, 13:38 - Girlfriend: weet niet
will be split into this list:
['', '8/7/15', ', ', '13:38', 'Girlfriend', ':', ' weet niet\n']
Every message is parsed in this logical way allowing me to assign the respective indices to their properties, giving rise to the following list logic expressed in pseudocode:
i = 0
date_list = text_list[i+1]
time_list = text_list[i+3]
username_list = text_list[i+4]
message_list = text_list[i+6]
and seeing that every message always has a total of 7 properties iterating over this long list was trivial. This generated 4 seperate lists.
Order the data
Having seperate lists was nice but still made it a bit fiddly to iterate over, although every message with their respective properties shared the same index I preferred to have them in dictionaries. In hindsight a dataframe with the seperate lists as indices would've made this analysis far quicker and easier, but not knowing exactly how to do it in pandas, but do knopwing how to do it exactly in Python itself, made me choose the Python way: I wanted results ASAP and without a hassle.
Each username gets their own dictionary with the username as key and the messagelist as property. With each username having their own list of messages, I still needed to split each message in separate words. Splitting each message in a list of seperate words only left me to unfold this nested structure into a single word structure. At this point I knew I would get skewed results as typo's were interpreted as seperate words, fixing this is a non-trivial task and I didn't think I could do this in a single evening.
With a complete word list of each username over the entire timespan it was now an easy task to generate some statistics from:
Girlfriend as the following amount of messages: 19175
Casper has the following amount of messages: 20822
Girlfriend has an average word length of: 3.7944
Casper has an average word length of: 3.8425
Girlfriend has said 5323 unique words.
Casper has said 6906 unique words.
And a top 50 of most used words:
Girlfriend:
[('ik', 1415), ('je', 1241), ('', 1171), ('is', 748), ('en', 748), ('ja', 716), ('ben', 535), ('heb', 507), ('maar', 466), ('niet', 425), ('dat', 423), ('wat', 398), ('oh', 393), ('de', 382), ('me', 375), ('zo', 373), ('jaa', 359), ('t', 338), ('een', 318), ('oke', 315), ('jaaa', 315), ('kan', 313), ('hee', 305), ('in', 303), ('ga', 296), ('nee', 284), ('heee', 276), ('wel', 270), ('we', 262), ('met', 249), ('die', 248), ('dan', 247), ('wil', 243), ('haha', 238), ('hahaha', 236), ('op', 229), ('van', 225), ('of', 216), ('nog', 215), ('moet', 205), ('dus', 197), ('ook', 196), ('was', 190), ('er', 186), ('voor', 184), ('het', 177), ('k', 171), ('hoe', 168), ('nu', 165), ('geen', 164)]
Casper:
[('je', 2344), ('ik', 1954), ('en', 1238), ('is', 1228), ('het', 1189), ('dat', 989), ('de', 919), ('', 893), ('ja', 841), ('niet', 784), ('maar', 757), ('wat', 755), ('k', 720), ('ben', 674), ('heb', 662), ('zo', 634), ('wel', 629), ('hoe', 615), ('die', 612), ('een', 602), ('met', 574), ('he', 548), ('van', 546), ('in', 523), ('dan', 474), ('nog', 473), ('haha', 463), ('er', 449), ('ga', 410), ('was', 405), ('te', 402), ('voor', 395), ('ook', 391), ('me', 391), ('kan', 384), ('n', 379), ('op', 358), ('we', 345), ('aan', 334), ('heee', 321), ('nee', 304), ('jij', 287), ('naar', 287), ('of', 281), ('nu', 279), ('als', 277), ('al', 273), ('wil', 271), ('mijn', 269), ('echt', 259)]
Plotting the list of values gives a distribution one would expect from a word frequency distribution of a given corpus: wiki link to Zipf's Law
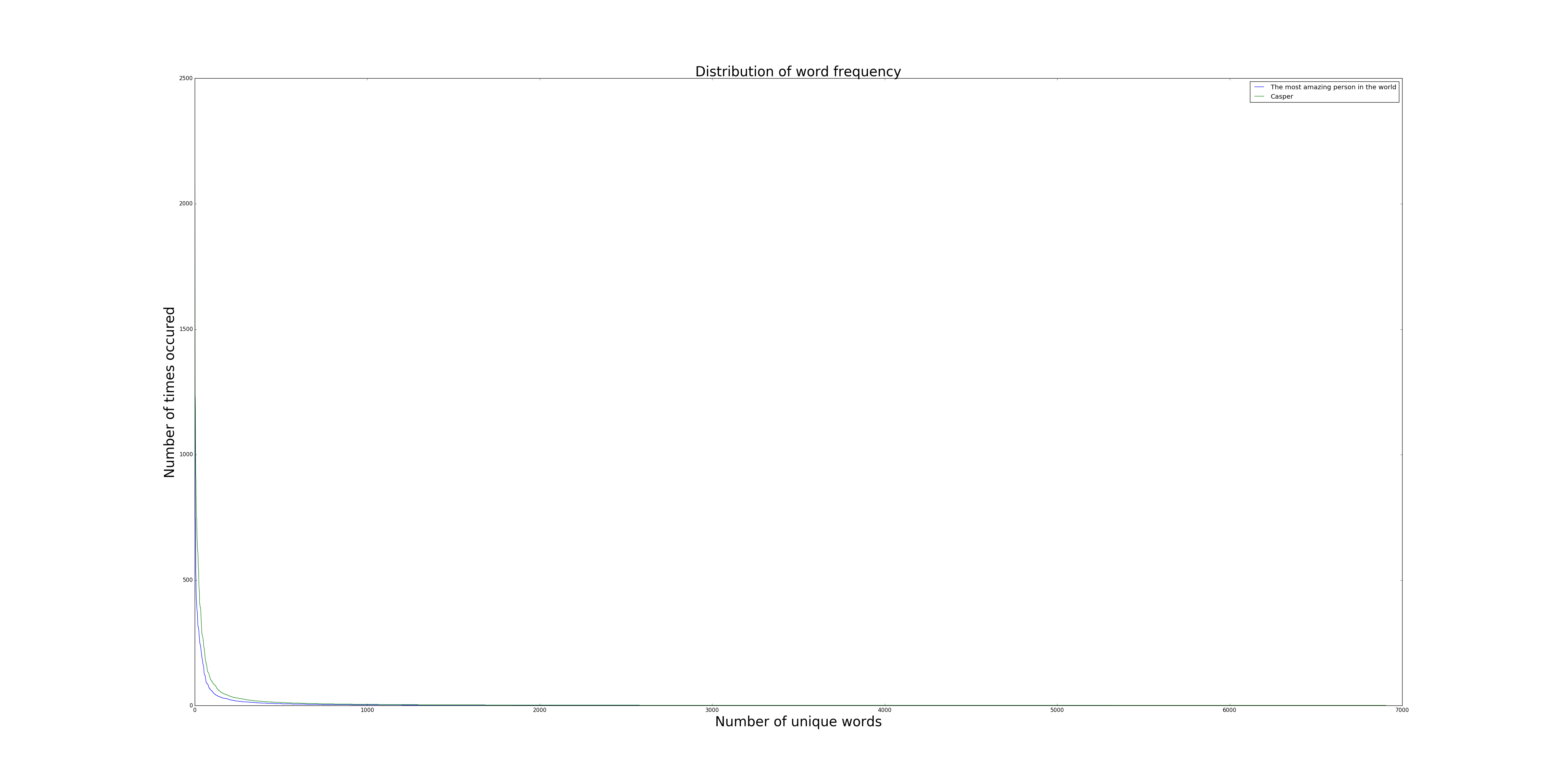
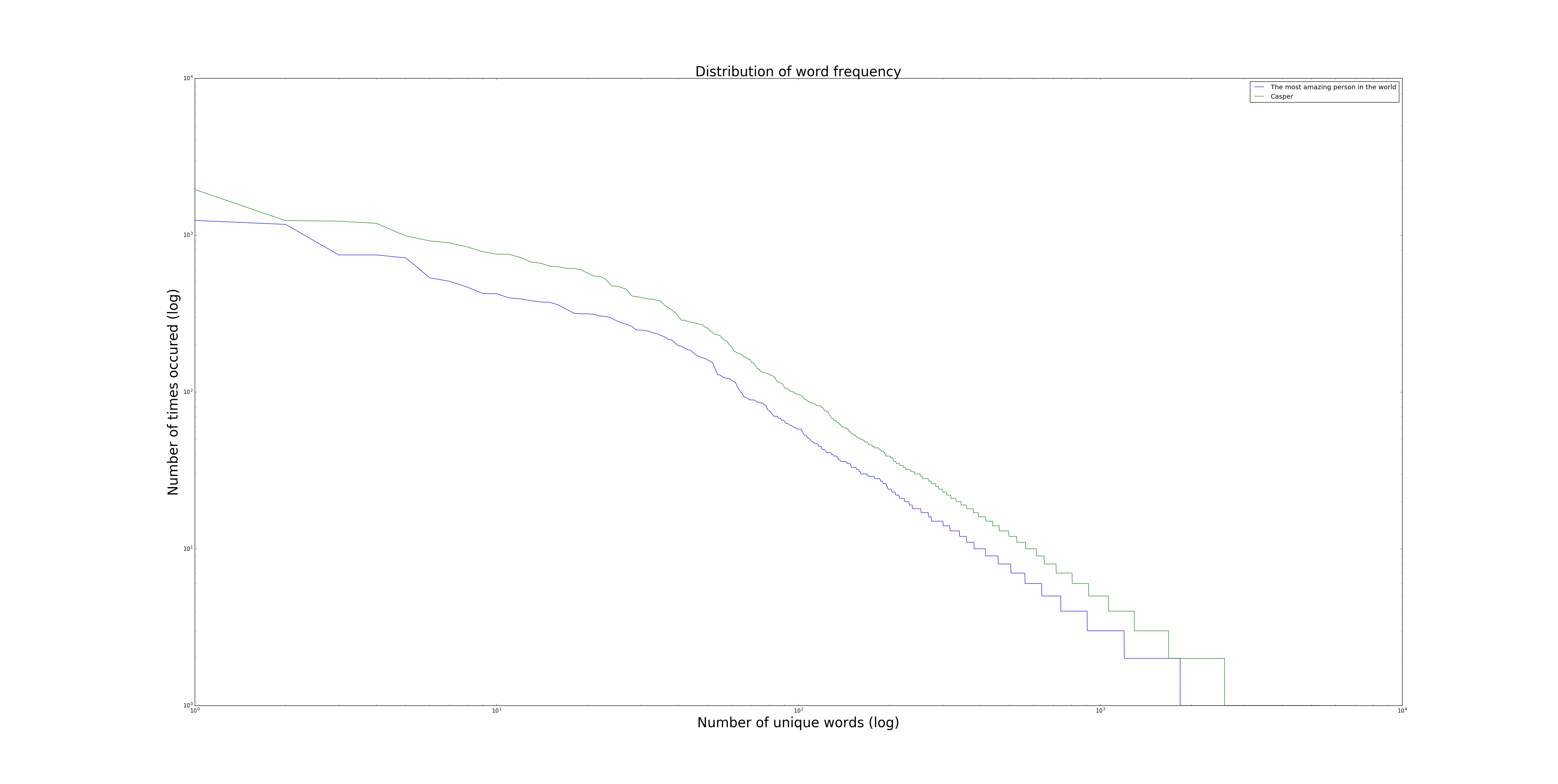
Being close to a power law, I figured it's more valuable to view them with both axis as logarithms:
More Statistics
At this point I actually already had what I was looking for, I knew how often my girlfriend and I used a specific word. She said it way less often than I expected: 84 times. I thought it was somewhere in the hundreds, but then again, this might be the case if the corpus would be corrected for typos - and typos do happen often when talking over chat with a cell phone.
Having seperate date & time lists, I wanted to exploit these features. The story about generating these plots is very similar to the above. Though one thing to note is that for working with the dates I converted both the timestamps and the datestamps to unix time (if only I used the pandas Datetime functionality!) and worked my way up from there.
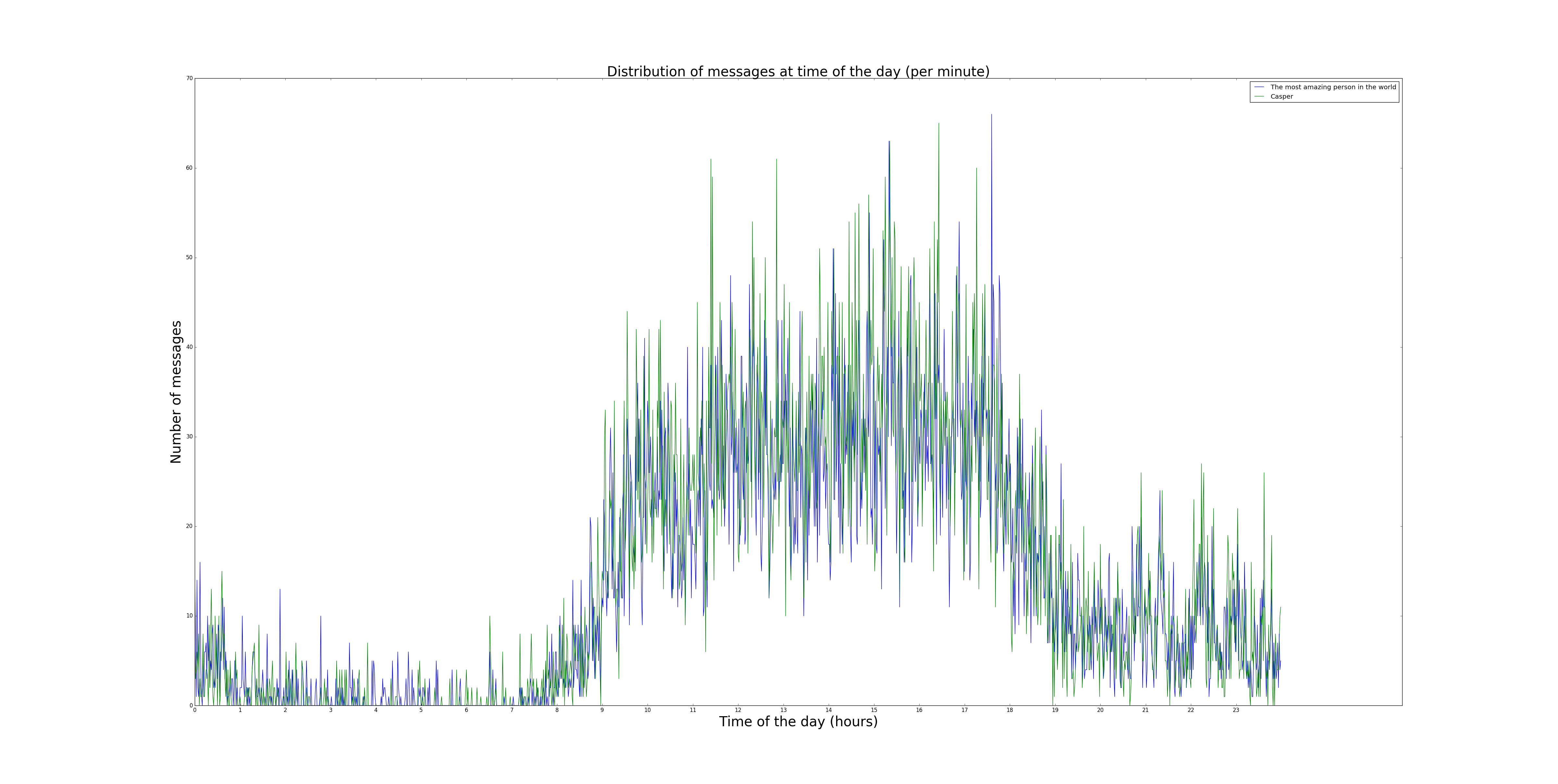
With a list of unix times I wanted to see how often we messaged at what time of the day. As expected the largest activity is during the day, with a sharp rise in the morning and a mild drop when approaching the evening. What I do find noteable about this is at the hours (20-24) there seems to be a dampened sine, the exact reason for this is unclear to me but I do find it interesting. Also notice how my girlfriend never said anything in the history of our chat between 6:00 and 6:30, funny.
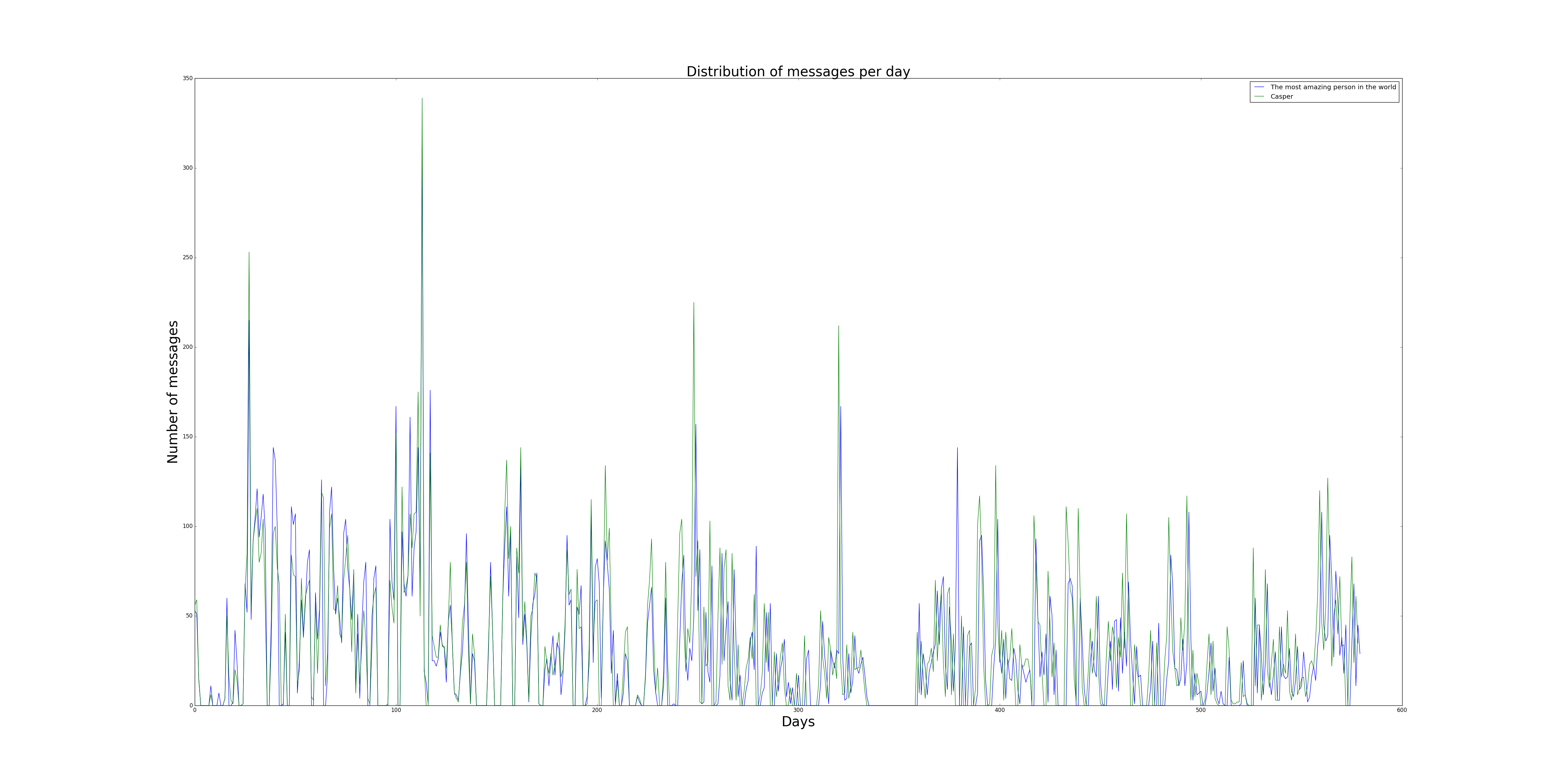
Still working with the timestamps, I also wanted to know how often we chatted across the timespan of the chat. Below you can see how many messages we've send on a given day. One thing that stands out is the flatline starting at day 335 and ending around day 359. This month is a month I did not had a cell phone as my previous one was broken and I wanted to see how a month would be without a cellphone. The peaks represent a long conversation on that given day.
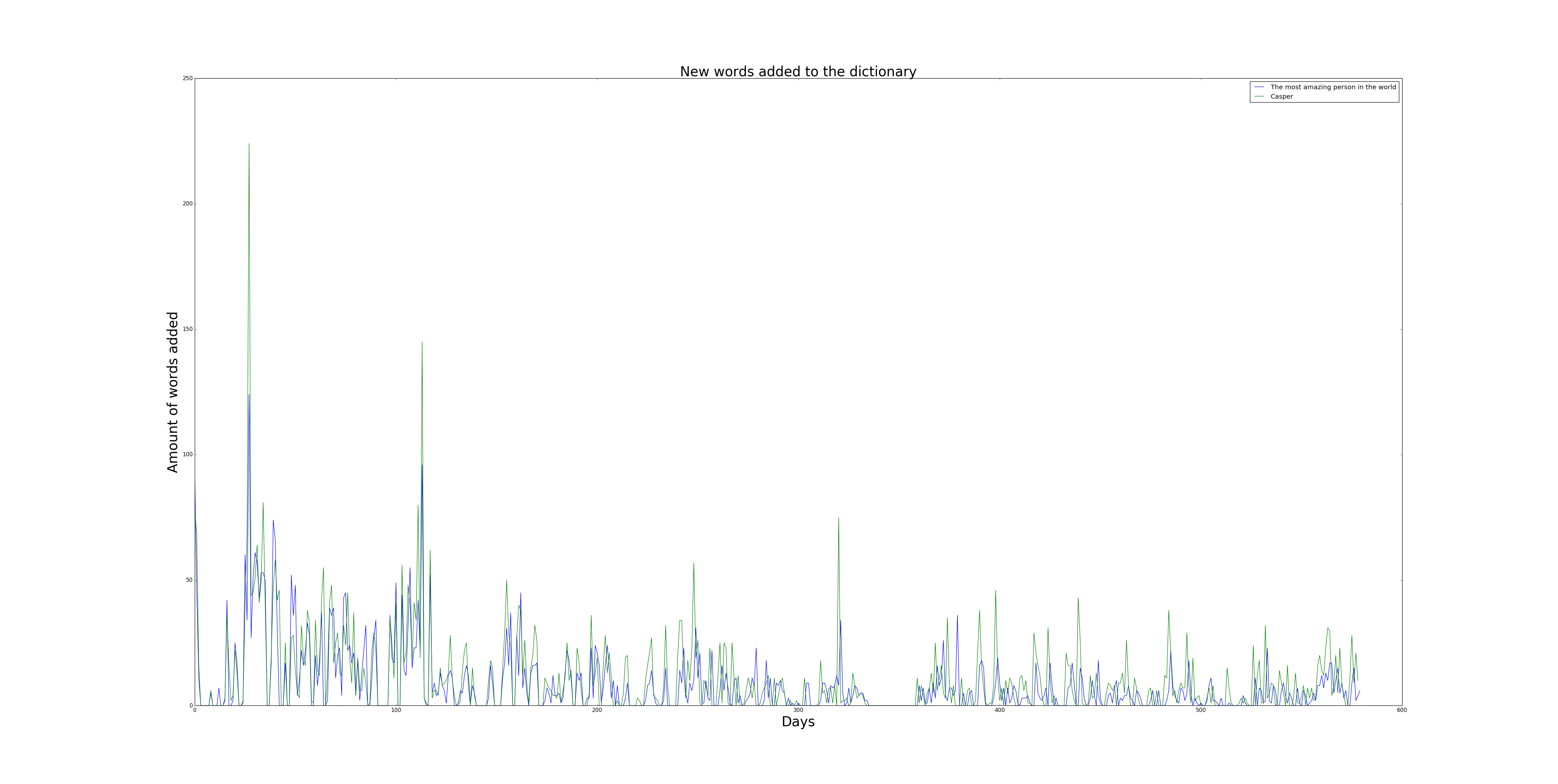
Finally I wanted to see how the dictionary of unique words grew over time. Below is a plot of new words added to our personal dictionary. The dictionary started of with 0 words and gew to a final of 5323 unique words for my girlfriend and 6906 for myself. Notice how the peaks correlate with the above plot, but also note that there is a slight declining trend in the peaks over time. The correlation can easily be explained by the amount of messages send each day, whenever a long conversation happens one needs to use new words for whatever reasons and so new words get added. The slightly declining trend can be explained by repetition of words and eventually one keeps on falling back to the same word over and over.
This is everything the code can generate, and it was a fun evening coding this. Also the word I was looking for that originally started this idea was: poep, yeah.